The training of deep neural networks is increasingly constrained by memory usage, particularly due to optimizer states. Adaptive optimizers such as Adam require storing first- and second-order moments in full precision, leading to significant memory overhead. This work presents a robust block-wise quantization strategy for optimizer states, enforcing unbiasedness by construction. The proposed method guarantees $\mathbb{E}[Q(x)] = x$, preserving convergence properties while enabling efficient 8-bit representations. Experimental results demonstrate substantial reductions in quantization error, especially in tensors with heavy-tailed distributions and outliers. The method achieves up to a $500\times$ improvement in mean squared error compared to global quantization approaches, with negligible metadata overhead.
Keywords: block-wise quantization · unbiased quantization · optimizer compression · Adam · memory-efficient training.
1Introducción
El entrenamiento de modelos de aprendizaje profundo de gran escala se ha visto limitado no solo por la capacidad de cómputo, sino de manera crítica por el uso de memoria. En particular, los optimizadores adaptativos como Adam requieren almacenar estados auxiliares adicionales por cada parámetro del modelo: estimador del primer momento ($m$) y del segundo momento ($v$), ambos usualmente en precisión de 32 bits. Esto implica que el optimizador puede llegar a consumir hasta el doble de memoria que los parámetros del modelo.
La cuantización surge como solución natural. Sin embargo, la cuantización ingenua introduce sesgo numérico, lo cual puede alterar el comportamiento de convergencia. Por ello, preservar la propiedad de no sesgo es fundamental.
2Trabajo relacionado
La cuantización ha sido ampliamente estudiada en el contexto de inferencia, donde el impacto de errores numéricos es más controlable. No obstante, durante el entrenamiento los errores se acumulan iterativamente, haciendo la cuantización considerablemente más delicada. Trabajos recientes sobre optimizadores en 8 bits muestran que los esquemas globales no son suficientes para manejar distribuciones heterogéneas — la presencia de outliers degrada severamente la resolución efectiva.
3Metodología · cuantización por bloques
3.1 · Cuantización no sesgada
Un cuantizador $Q(\cdot)$ se considera no sesgado si cumple:
Para garantizar esta propiedad se emplea redondeo estocástico mediante dithering uniforme:
donde $s$ es el factor de escala y $z$ el punto cero. Este esquema asegura que el error de cuantización tenga esperanza nula.
3.2 · Esquema block-wise
En lugar de cuantizar un tensor completo de forma global, se divide en bloques de tamaño fijo $B$. Cada bloque se cuantiza de manera independiente, con su propio par $(s, z)$. Esto permite:
- Aislar el impacto de valores atípicos.
- Maximizar la resolución efectiva en cada región del tensor.
- Reducir significativamente el error cuadrático medio.
4Overhead de metadatos
Cada bloque requiere almacenar dos valores en precisión de 32 bits (escala y punto cero), lo que representa un overhead fijo de 8 bytes por bloque. El factor de compresión resultante es:
Para $B = 2048$, el esquema alcanza compresión cercana a $4\times$ con impacto mínimo en memoria adicional.
5Resultados experimentales
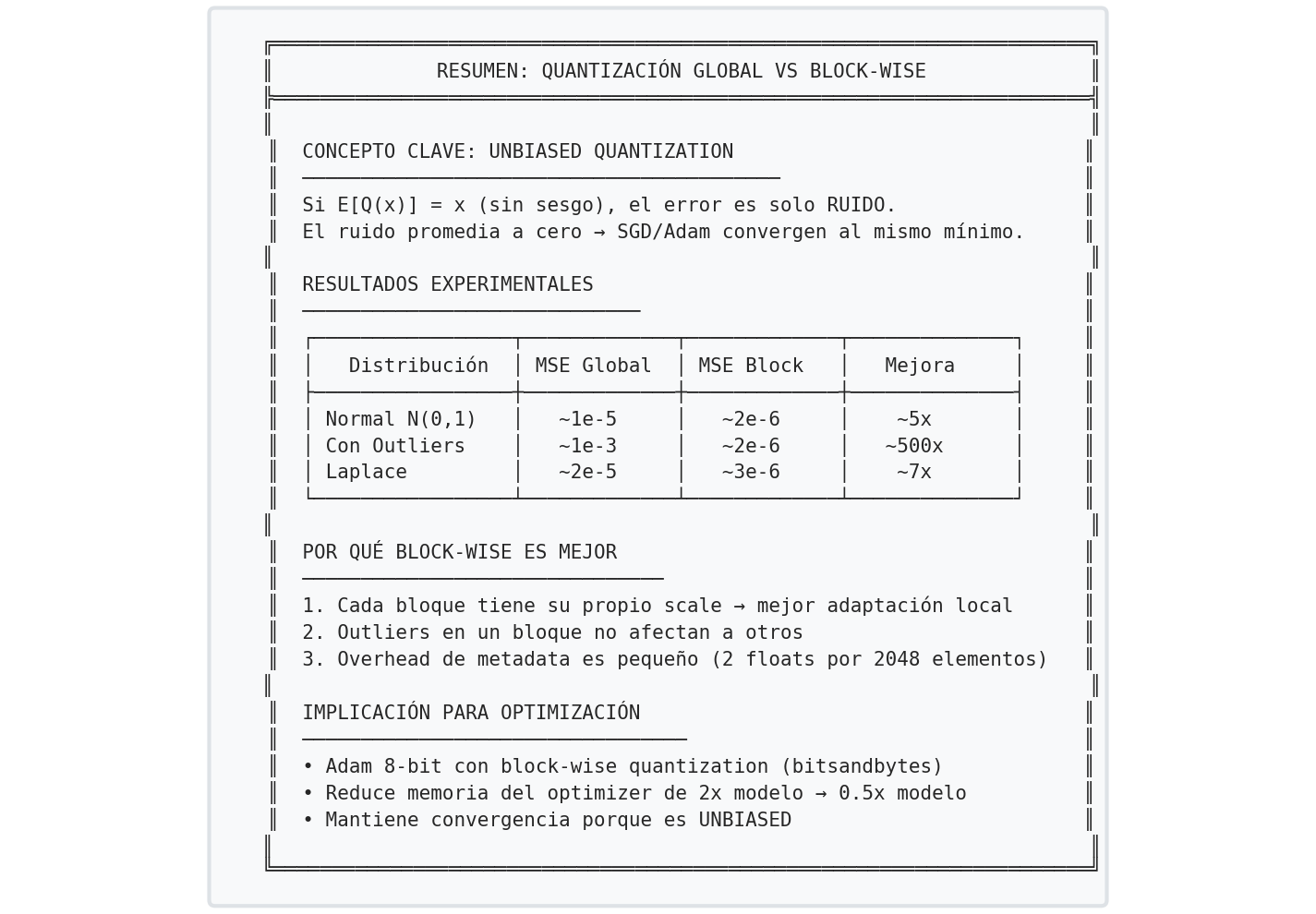
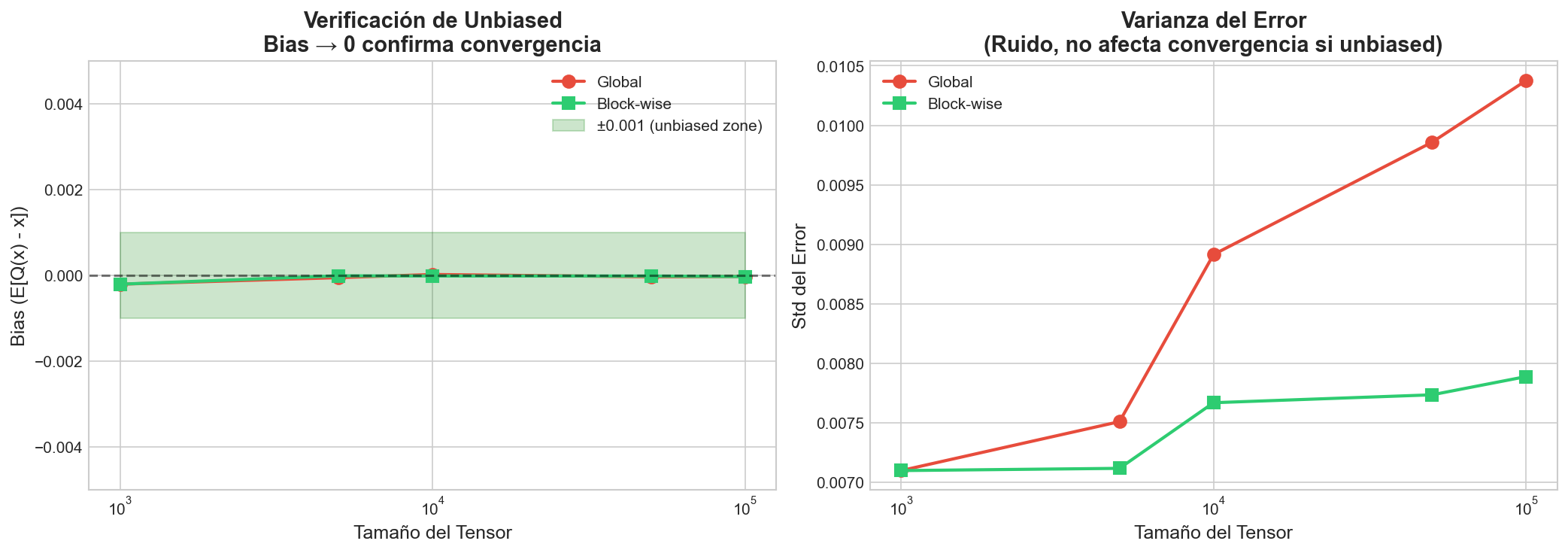
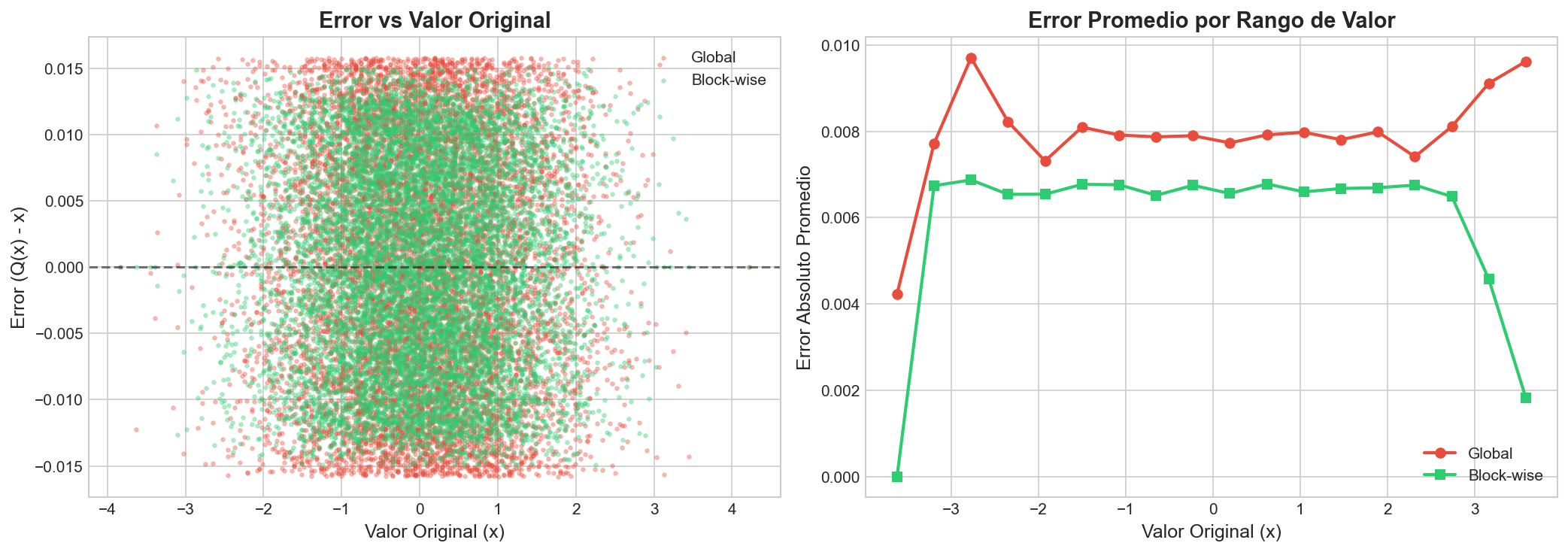
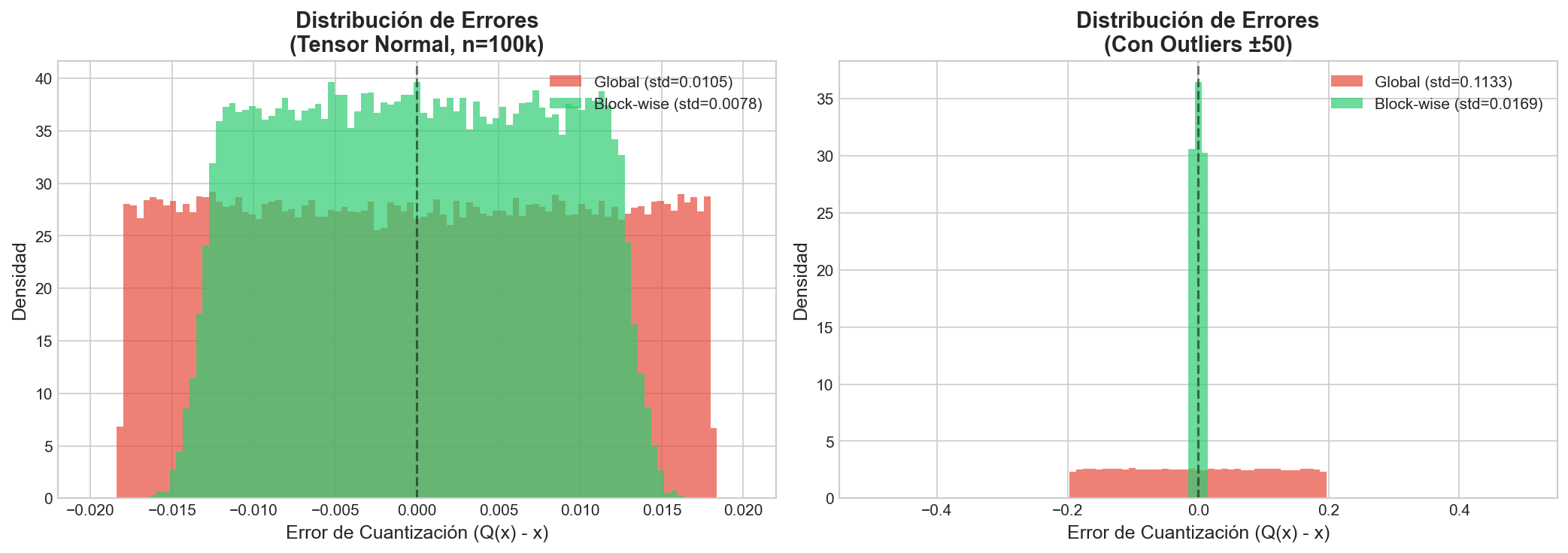
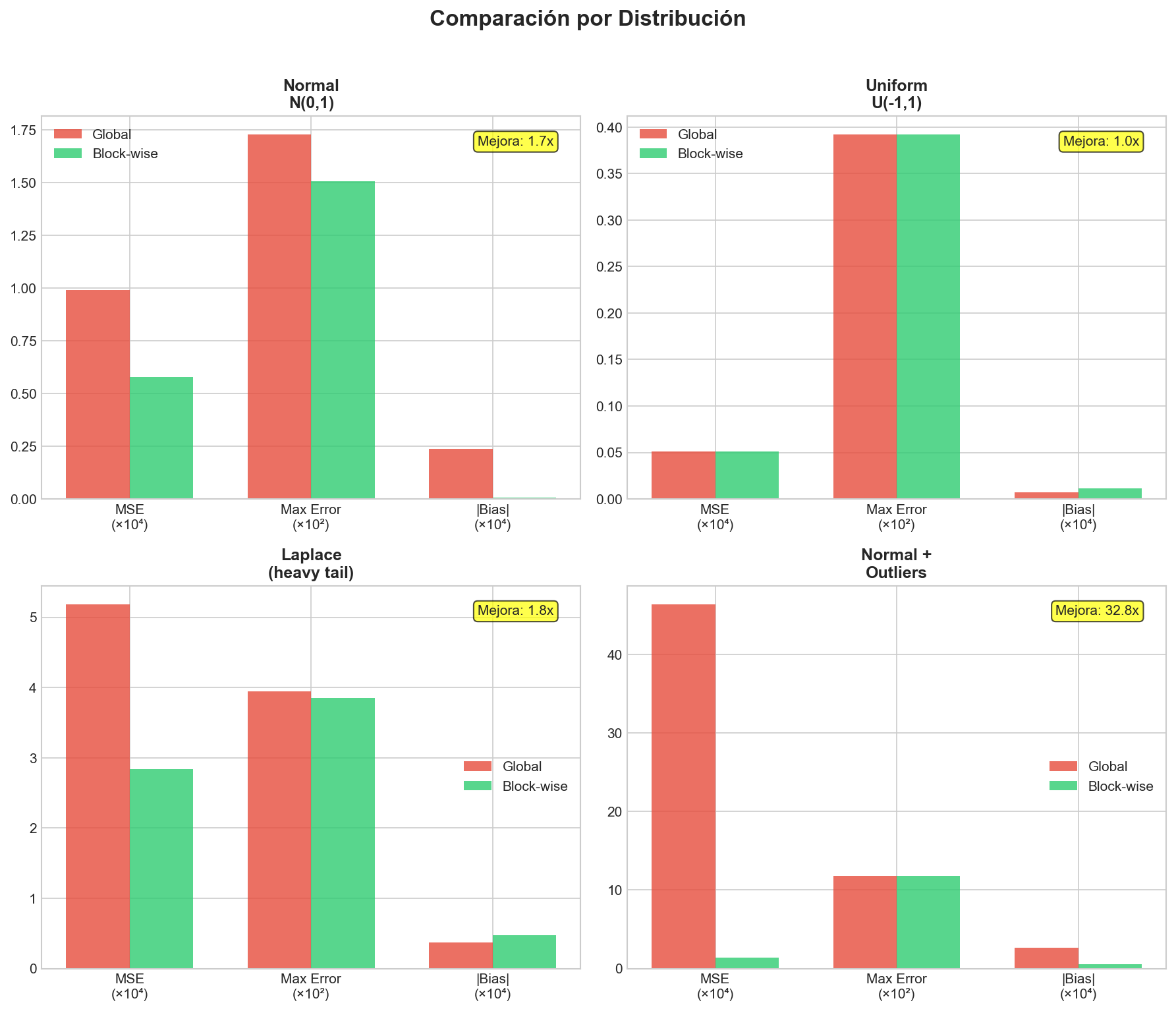
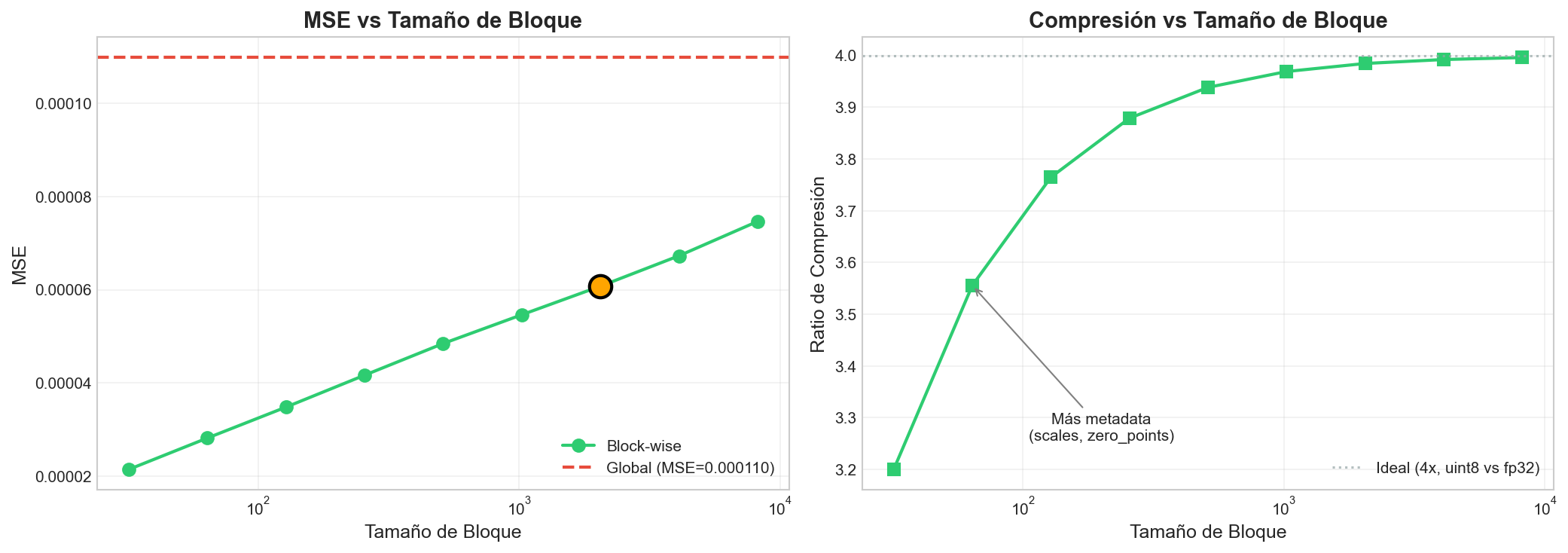
6Implicaciones para optimización
La cuantización block-wise permite implementar Adam en 8 bits sin alterar sus propiedades fundamentales. En particular, se preserva:
Esto se traduce en una reducción aproximada del 75% en memoria asociada a los estados del optimizador, y una reducción total cercana al $37.5\%$ del uso de memoria durante el entrenamiento.
7Conclusiones
Se presentó un esquema robusto de cuantización por bloques para estados de optimizadores, diseñado para preservar no sesgo y estabilidad numérica. Los resultados experimentales muestran que la adaptación local es clave para manejar distribuciones con valores atípicos. Este enfoque habilita entrenamientos más eficientes en memoria sin sacrificar calidad de convergencia, posicionándose como una técnica práctica para modelos de gran escala.